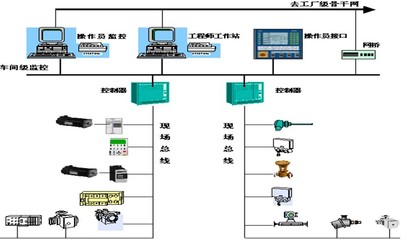
Linux系統管理員必備的12個基礎架構監控工具與報警系統開發指南
在當今復雜的基礎架構環境中,有效的監控和及時的報警是確保系統穩定性和業務連續性的關鍵。作為Linux系統管理員,掌握一系列強大的監控工具并構建高效的報警系統是必不可少的技能。本文將介紹12個基礎架構監控工具,并探討如何基于這些工具開發報警系統。
一、12個必備的監控工具
- Nagios - 經典的開源監控系統,支持廣泛的插件和通知機制,適合監控主機、服務和網絡。
- Zabbix - 功能全面的企業級監控解決方案,具備自動發現、實時繪圖和靈活的報警配置。
- Prometheus - 專為云原生環境設計的監控和警報工具包,采用拉模型和強大的查詢語言PromQL。
- Grafana - 可視化工具,常與Prometheus、InfluxDB等數據源結合,創建直觀的監控儀表板。
- Netdata - 實時性能監控工具,提供低延遲的指標收集和精美的Web界面。
- Icinga - Nagios的分支,具有現代化的Web界面和更靈活的配置選項。
- Cacti - 基于RRDTool的網絡圖形化監控工具,擅長繪制歷史數據趨勢圖。
- Monit - 輕量級的進程監控工具,可自動重啟失敗的服務,適合單機監控。
- CollectD - 系統統計信息收集守護進程,可將數據發送到多種存儲后端如InfluxDB。
- Sysdig - 系統級別的故障排查和監控工具,提供容器可見性和安全監控。
- Elastic Stack(ELK) - 由Elasticsearch、Logstash和Kibana組成,用于日志集中管理和分析。
- Telegraf - InfluxDB的數據收集代理,支持眾多輸入插件,易于集成到現有監控體系。
二、報警系統的開發
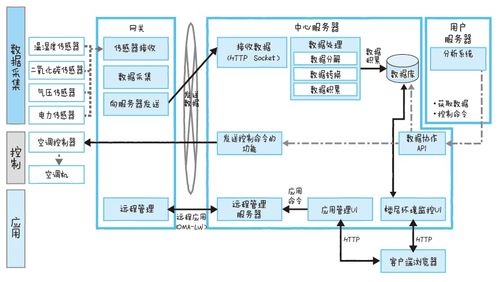
一個高效的報警系統應包含以下核心組件:
- 數據收集層 - 使用上述工具(如Prometheus、Telegraf)收集指標和日志數據。
- 規則引擎 - 定義報警條件,例如CPU使用率超過90%持續5分鐘,或服務端口不可達。
- 通知渠道 - 集成多種通知方式,包括郵件、短信(通過Twilio等API)、Slack、釘釘、微信、PagerDuty等。
- 報警聚合與降噪 - 避免報警風暴,對相關報警進行分組和抑制,確保重要報警不被淹沒。
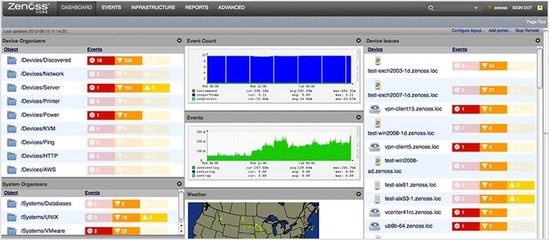
- 可視化與儀表板 - 利用Grafana或Kibana創建實時監控視圖,幫助快速定位問題。
- 自愈機制 - 結合自動化腳本(如Ansible、SaltStack)或工具(如Monit),在檢測到特定問題時自動執行修復操作。
三、實施建議
- 分層監控:從基礎設施層(服務器、網絡)到應用層(服務、數據庫)進行全方位監控。
- 黃金信號:重點關注延遲、流量、錯誤和飽和度四個關鍵指標。
- 測試報警:定期測試報警通道的有效性,確保在真實故障時報警能及時送達。
- 文檔化:為每個報警規則編寫文檔,說明觸發條件、影響范圍和應急處理步驟。
四、
構建監控和報警系統是一個持續迭代的過程。Linux系統管理員應根據實際環境選擇合適的工具組合,并不斷優化報警策略,以實現從被動響應到主動預防的轉變。通過上述工具和方法的有效應用,可以顯著提升系統的可靠性和運維效率。
如若轉載,請注明出處:http://www.zyyaa.com/product/92.html
更新時間:2026-05-10 11:14:02